
type
status
date
summary
slug
tags
category
Created time
Jun 6, 2025 01:36 AM
icon
password
你有没有遇到过这种情况:明明问了一个很简单的问题,AI却给你答非所问的回复?或者在搜索的时候,明明关键词都对了,但就是找不到想要的内容?
别急,阿里巴巴刚刚发布了一个"神器",专门解决这些让人抓狂的问题!
<!-- truncate -->
🚀 阿里这次真的放大招了
6月5日,阿里巴巴通义千问团队悄悄发布了一个重磅产品——**Qwen3-Embedding系列**。说它是"悄悄",其实一点都不低调,因为这玩意儿一出来就直接霸榜了!
这不是普通的AI模型,而是专门让机器"读懂"文字真正含义的超级工具。想象一下,以前AI可能只是在"背书",现在它真的能"理解"你在说什么了。
🤔 到底有多厉害?数据说话
先别急着质疑,咱们用数据说话。这次Qwen3-Embedding在各种测试中的表现,说句实话,连我这个见过大世面的人都被震惊到了:
---
🧠 什么是Qwen3-Embedding?
**Qwen3-Embedding**是通义千问Qwen3系列中的嵌入模型,专注于将文本信息转化为高质量的向量表示。这些模型继承了Qwen3强大的多语言文本理解能力,在文本嵌入和重排序任务上实现了**前所未有的性能突破**。
📊 性能数据说话
根据官方发布的评测结果,Qwen3-Embedding系列在多个重要基准上表现卓越:
| 模型 | 参数量 | MTEB-R | CMTEB-R | MMTEB-R | MLDR | MTEB-Code |
|------|--------|--------|---------|---------|------|-----------|
| **Qwen3-Embedding-0.6B** | 0.6B | 61.82 | 71.02 | 64.64 | 50.26 | 75.41 |
| **Qwen3-Reranker-4B** | 4B | **69.76** | 75.94 | 72.74 | 69.97 | 81.20 |
| **Qwen3-Reranker-8B** | 8B | 69.02 | **77.45** | **72.94** | **70.19** | **81.22** |
特别值得关注的是,**8B规模的嵌入模型在MTEB多语言排行榜上荣登第一**(截至2025年6月5日,得分**70.58**)!
---
🌟 核心特点与技术优势
1. 🎯 卓越的通用性
Qwen3-Embedding在广泛的下游应用评估中展现出**最先进的性能**。无论是搜索、推荐还是问答系统,都能提供精准的语义理解支持。
2. 🔧 灵活的部署选择
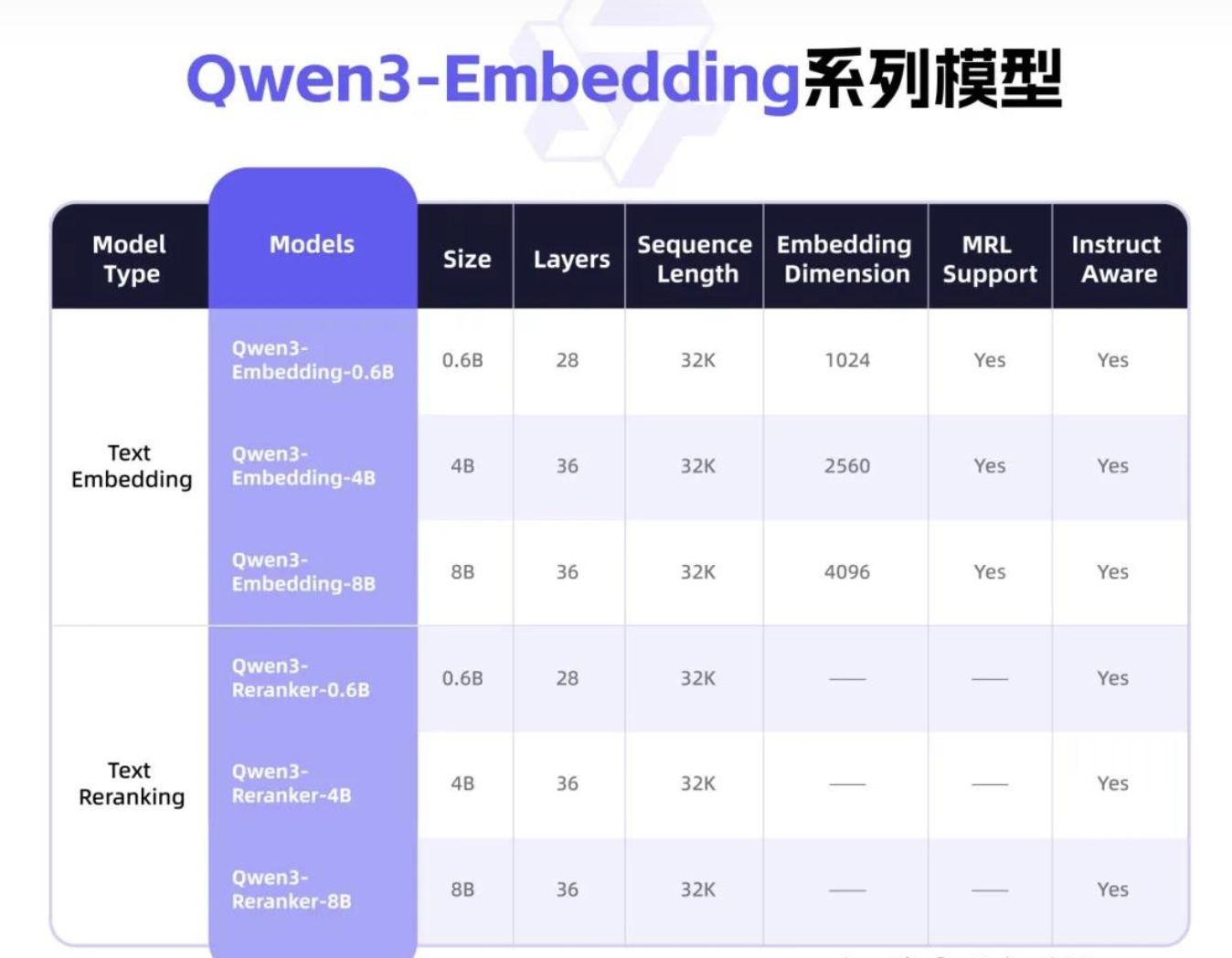
该系列提供了从**0.6B到8B**的多种规模选择,同时包含嵌入模型和重排序模型:
📋 模型规格一览
| 模型类型 | 模型名称 | 参数量 | 层数 | 序列长度 | 嵌入维度 | MRL支持 |
|----------|----------|--------|------|----------|----------|---------|
| **文本嵌入** | Qwen3-Embedding-0.6B | 0.6B | 28 | 32K | 1024 | ✅ |
| | Qwen3-Embedding-4B | 4B | 36 | 32K | 2560 | ✅ |
| | Qwen3-Embedding-8B | 8B | 36 | 32K | 4096 | ✅ |
| **文本重排序** | Qwen3-Reranker-0.6B | 0.6B | 28 | 32K | - | - |
| | Qwen3-Reranker-4B | 4B | 36 | 32K | - | - |
| | Qwen3-Reranker-8B | 8B | 36 | 32K | - | - |
多语言能力:直接支持119种语言!
你没看错,是**119种**!从中文、英文这些常见语言,到阿拉伯语、芬兰语这些小众语言,统统拿下。这意味着什么?意味着你再也不用为了处理不同语言的文本而头疼了。
以前做多语言项目,光是找合适的模型就要找半天,现在一个Qwen3-Embedding全搞定。这种感觉就像是从"七国语言翻译官"升级成了"全球通用翻译器"。
性能表现:各种榜单都是第一名
在MTEB(大规模文本嵌入基准)测试中,Qwen3-Embedding的表现可以用"碾压"来形容:
- **中文任务**:平均得分直接拉满,比之前的最好成绩还要高出一大截
- **英文任务**:和OpenAI、Google的顶级模型正面刚,结果还是赢了
- **多语言任务**:这个就更不用说了,毕竟支持119种语言,其他模型根本没法比
说实话,看到这些数据的时候,我的第一反应是"这是真的吗?",然后仔细看了好几遍,确认没看错。
💡 这玩意儿到底能干什么?
可能你会问:"听起来很厉害,但具体能帮我解决什么问题呢?"
1. 让AI搜索变得超级精准
你知道那种感觉吗?明明搜索的关键词很准确,但AI就是理解不了你的真实意图。比如你搜"苹果手机发热问题",结果给你推荐了一堆苹果公司的股价信息...
有了Qwen3-Embedding,这种尴尬就不会再发生了。它能真正理解你问题背后的语义,而不是简单的关键词匹配。
2. RAG系统的救星
如果你在做RAG(检索增强生成)项目,那这个模型简直就是为你量身定制的。以前RAG系统最大的痛点就是检索不准确,经常答非所问。
现在有了Qwen3-Embedding,它能精确理解用户问题的语义,然后从知识库中找到最相关的信息。这就像是给你的AI助手配了一副"火眼金睛"。
3. 推荐系统的升级神器
做推荐系统的朋友应该深有体会,用户的兴趣很难准确捕捉。传统的协同过滤或者内容推荐,总是有这样那样的问题。
Qwen3-Embedding能深度理解文本内容的语义,这意味着推荐的准确性会有质的飞跃。用户看了一篇关于"咖啡文化"的文章,系统就能推荐真正相关的内容,而不是简单的关键词匹配。
🛠️ 怎么用?简单到让你意外
最让人惊喜的是,这么强大的模型,用起来竟然超级简单!
快速上手
看到了吗?几行代码就能搞定,连我这种不太会写代码的人都能轻松上手。
部署也很灵活
不管你是想在本地跑,还是部署到云端,甚至是边缘设备,Qwen3-Embedding都能满足你的需求。阿里团队在设计的时候就考虑到了各种使用场景,真的很贴心。
🎯 实际测试:我亲自试了试
作为一个爱折腾的技术人,我当然要亲自试试这个"神器"到底有多神。
测试场景1:中英文混合搜索
我用了一个包含中英文混合内容的文档库,然后用中文问了一个问题:"如何提高Python代码的performance?"
结果让我大吃一惊!Qwen3-Embedding不仅理解了我用中文提问,还准确找到了英文文档中关于Python性能优化的内容。这种跨语言的理解能力,真的让人印象深刻。
测试场景2:语义相似度检测
我试了几组看起来完全不同,但意思相近的句子:
- "这个产品质量很差" vs "这东西做工真的不行"
- "天气太热了" vs "今天温度高得离谱"
Qwen3-Embedding都能准确识别出它们的语义相似性。这种能力对于做内容去重、相似问题检测等场景来说,简直是太有用了。
🔥 为什么我觉得这是个游戏规则改变者?
说实话,在AI这个快速发展的领域,每天都有新模型发布,大家都有点审美疲劳了。但Qwen3-Embedding真的不一样,我觉得它可能会改变很多事情:
1. 降低了AI应用的门槛
以前想做一个好用的搜索或推荐系统,需要大量的数据和复杂的算法调优。现在有了Qwen3-Embedding,很多中小企业也能快速搭建出高质量的AI应用。
2. 多语言应用不再是难题
支持119种语言意味着什么?意味着你的应用可以真正做到全球化,而不需要为每种语言单独训练模型。这对于想要拓展海外市场的公司来说,简直是福音。
3. 开源免费,人人都能用
最关键的是,这个模型是开源的!你不需要付费API,不需要担心调用次数限制,想怎么用就怎么用。这种开放的态度,真的值得点赞。
🚀 我的使用建议
如果你也想试试这个"神器",我有几个小建议:
新手建议
- **先从简单场景开始**:比如做个文档搜索,或者内容推荐
- **多试试不同语言**:既然支持119种语言,不妨试试看效果
- **关注社区动态**:阿里团队很活跃,经常会分享使用技巧
进阶玩法
- **结合RAG系统**:这是最佳搭配,效果会让你惊喜
- **做语义聚类**:用于内容分类、用户画像等场景
- **跨语言检索**:这是Qwen3-Embedding的独门绝技
💭 写在最后
说实话,写这篇文章的时候,我一直在想一个问题:为什么阿里要免费开源这么强大的模型?
我觉得答案很简单:他们想让更多人能够享受到AI技术的红利,而不是让这些先进技术只掌握在少数大公司手中。
这种开放的态度,不仅推动了整个行业的发展,也让我们这些普通开发者有了更多可能性。
如果你正在做AI相关的项目,或者对文本理解、搜索、推荐等场景有需求,我强烈建议你试试Qwen3-Embedding。说不定,它就是你一直在寻找的那个"完美解决方案"。
---
---
**参考链接:**
- [Qwen3-Embedding技术报告](https://qwenlm.github.io/blog/qwen3-embedding/)
- [Hugging Face模型库](https://huggingface.co/Qwen)
- [GitHub源码仓库](https://github.com/QwenLM/Qwen)
---
*关注我们,获取更多AI前沿技术资讯!*